Towards speech translation without speech recognition
Sameer Bansal, Herman Kamper, Adam Lopez, Sharon Goldwater
current systems
|
source audio |
|
|
source text |
puede decirme el camino al hotel, por favor? |
|
target text |
can you tell me the way to the hotel please? |

current systems
|
source audio |
|
|
source text |
puede decirme el camino al hotel, por favor? |
|
target text |
can you tell me the way to the hotel please? |
~100 languages supported in Google Translate
written text availability
~3000 languages without a written form
Haiti earthquake, 2010
“Moun kwense nan Sakre Kè nan Pòtoprens”
People trapped in Sacred Heart Church, PauP
international rescue teams face language barrier
volunteers helped create parallel text corpora in a short time

availability of source language text
|
source audio |
|
|
source text |
? |
|
target text |
yes well and the car |
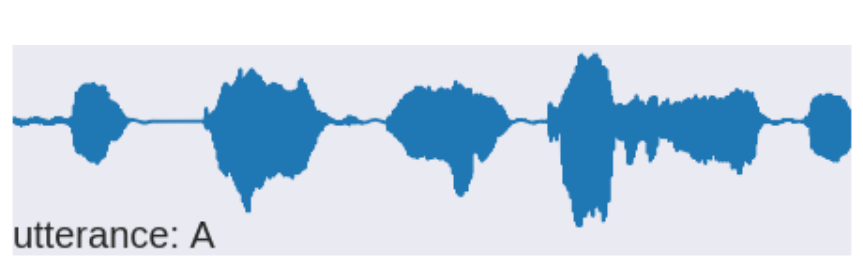
what can we do in this situation?
our work
|
source audio |
|
|
pseudo text |
c38c92 |
|
target text |
yes well and the car |
use a substitute for ASR
will this work?
an unsupervised state of the art speech-to-text toolkit
+
off-the-shelf standard machine translation toolkit
Yes ... but ...
Positives
learns some meaningful content word translations
~10 hours of training data
Negatives
big improvements required
CALLHOME Spanish dataset
- 50 telephone (~6 hours) calls
- transcriptions used for evaluation
- crowd-sourced English translations
- multiple speakers
acoustically real world conditions
speech-to-pseudotext using Unsupervised Term Discovery
find acoustic patterns
find acoustic patterns
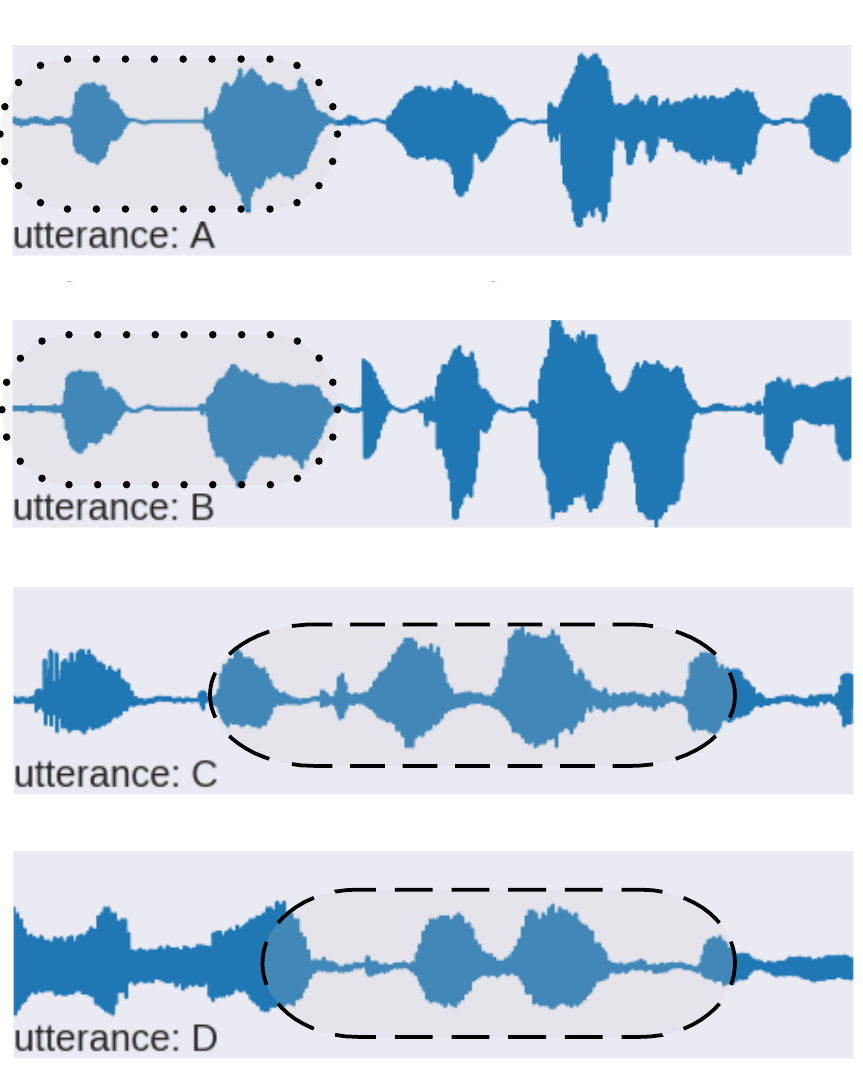
find acoustic patterns
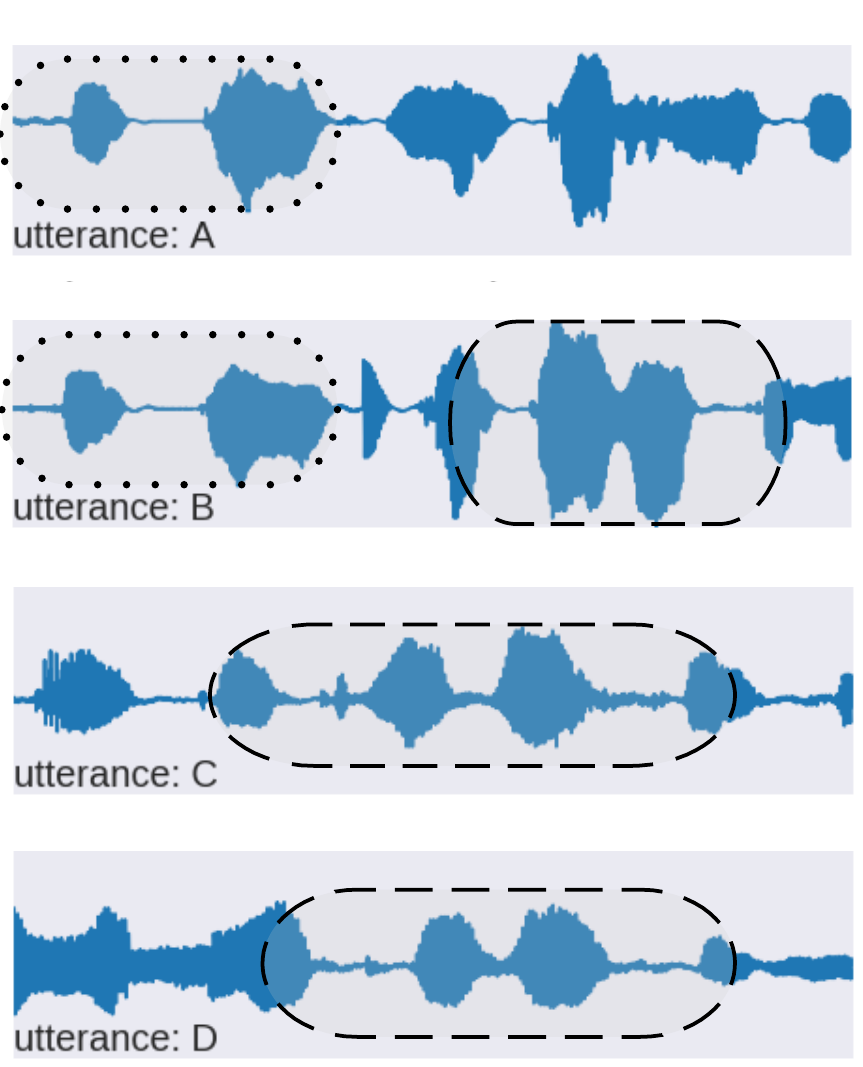
cluster patterns
using cluster ids as text representation
66% of clusters have errors
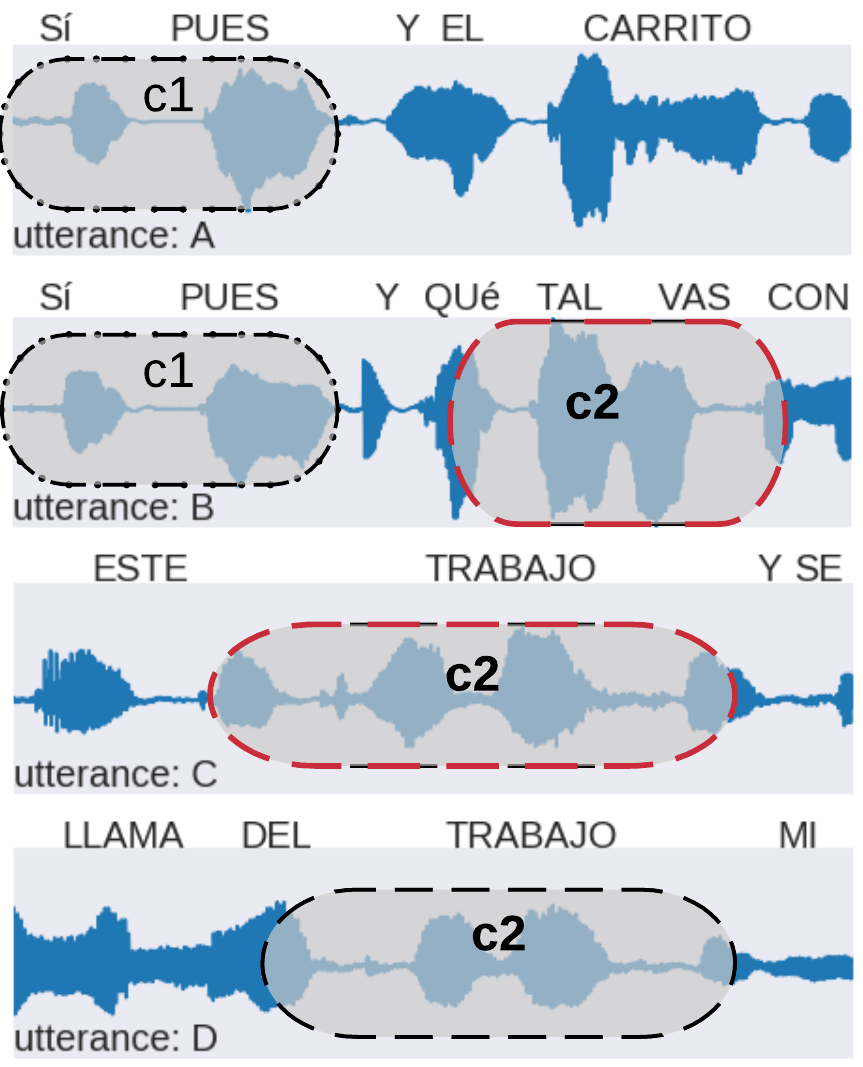
70% of the speech not covered by UTD
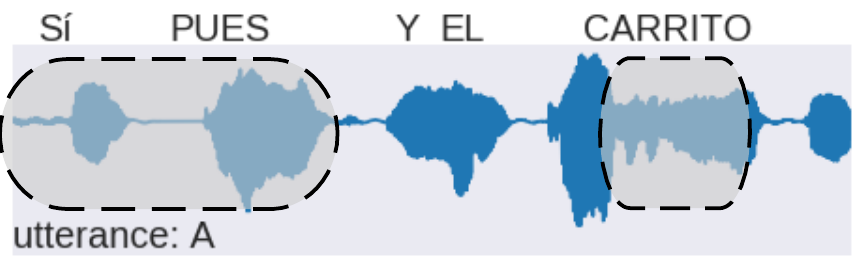
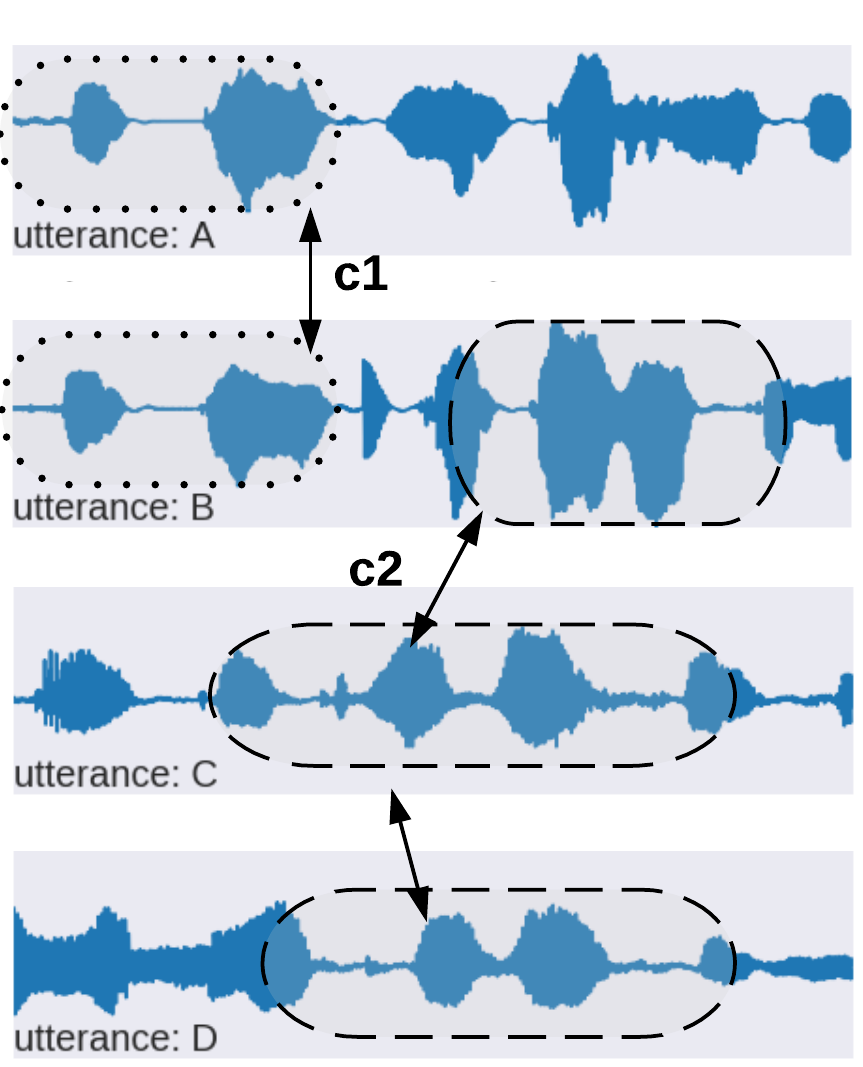
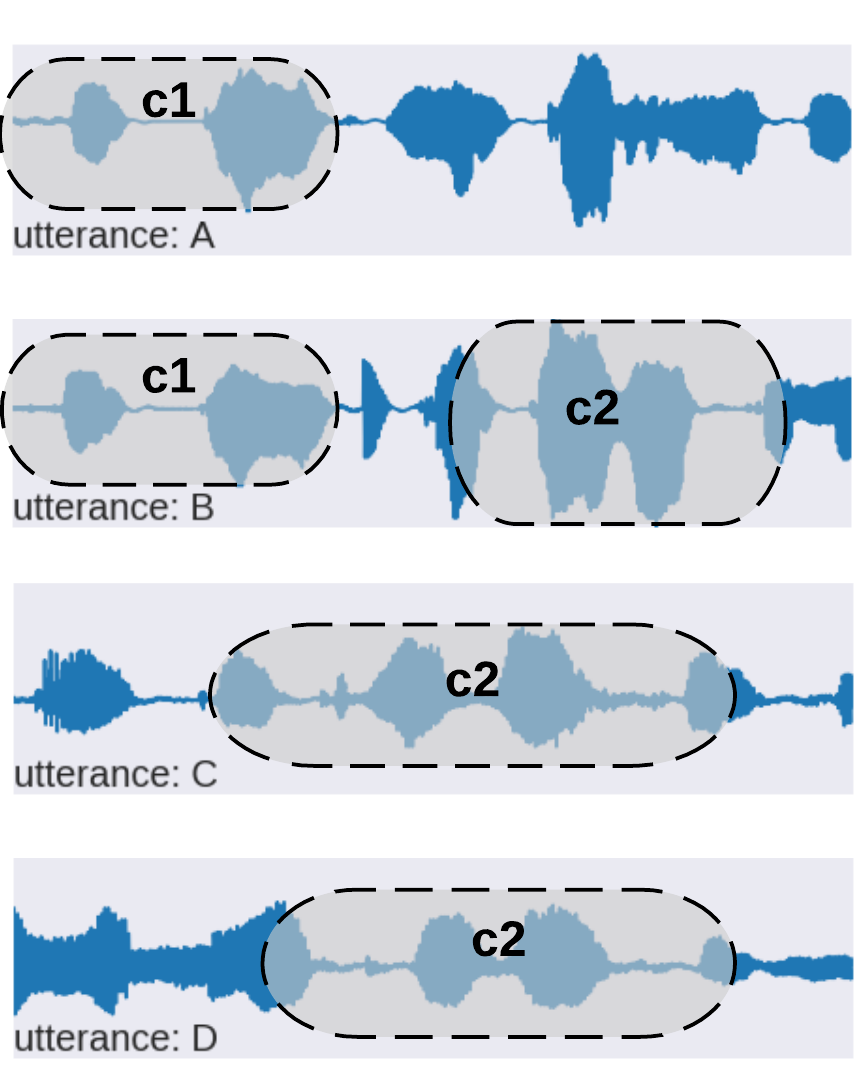
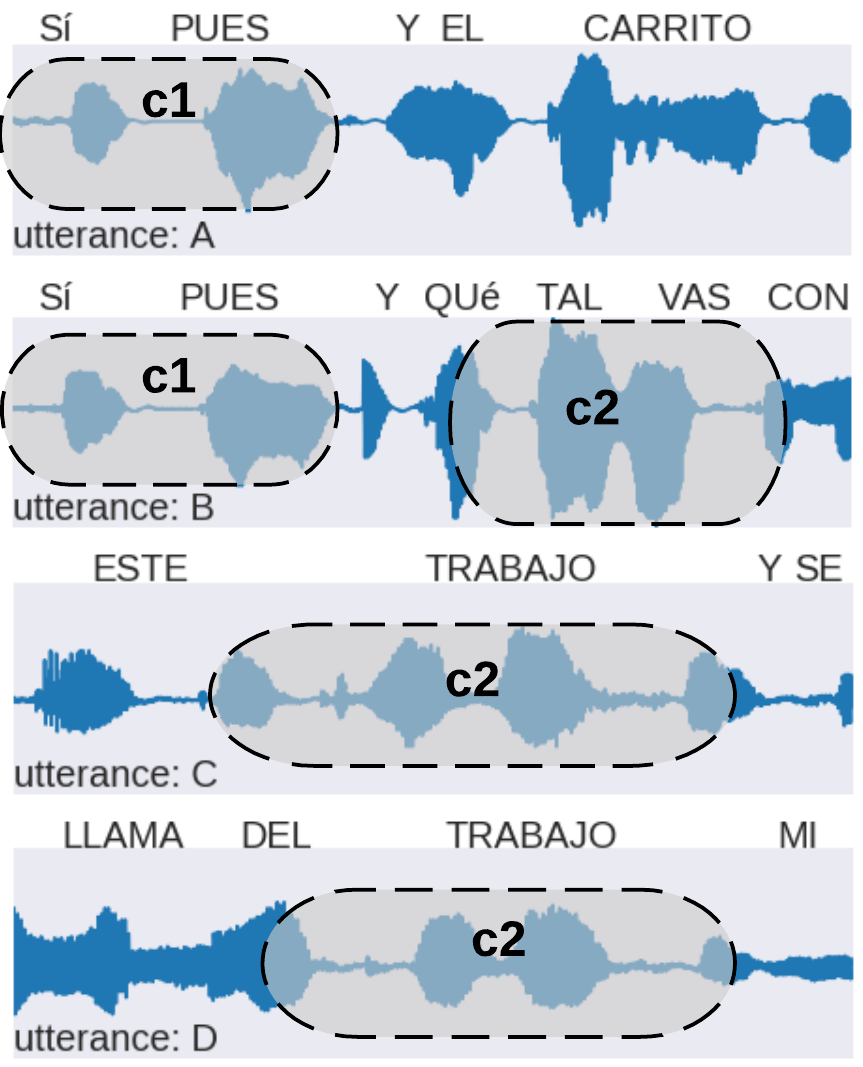
our model - parallel data
| audio utterance | pseudotext | human translation |
|---|---|---|
|
|
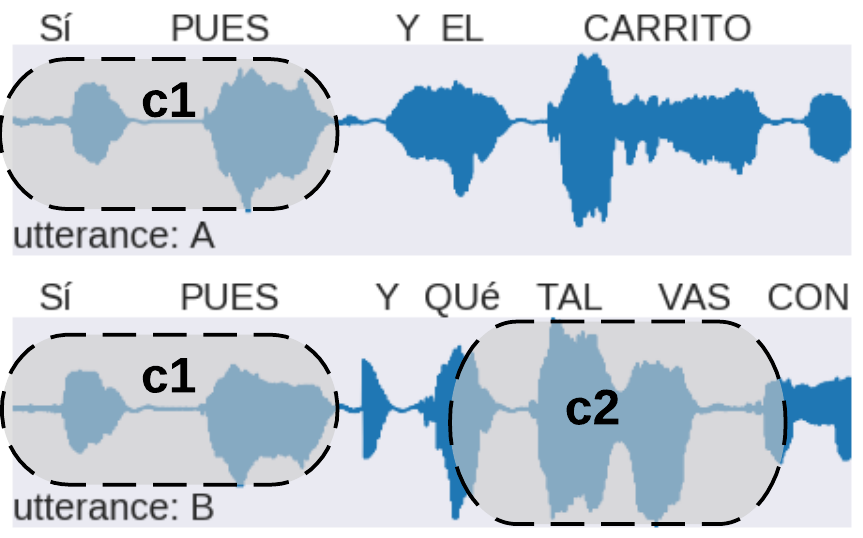
c1 | yes well and the car |
| c1 c2 | yes well and hows it going | |
| c2 | this work | |
| c2 | call him from work | |
IBM Model 1 : p(english word | cluster id)
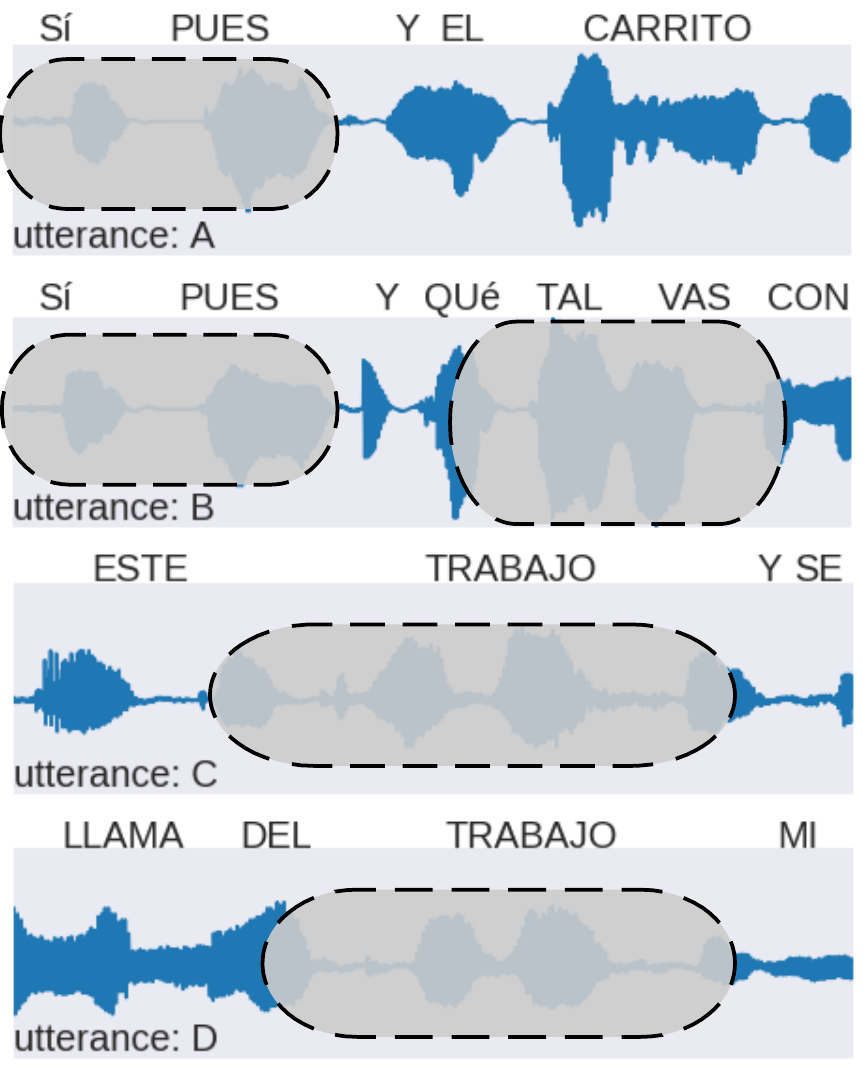
oracle model - parallel data
| transcription | human translation |
|---|---|
| sı́ pues y el carrito | yes well and the car |
| sı́ pues y qué tal vas con | yes well and hows it going |
| este trabajo y se | this work |
| llama del trabajo mi | call him from work |
IBM Model 1 : p(english word | source word)
translations
| audio utterances | prediction @ K=1 | human translation |
|---|---|---|
|
|
(yes) | yes well and the car |
| (yes) (job) | yes well and hows it going |
translations
| audio utterances | prediction @ K=2 | human translation |
|---|---|---|
|
|
(yes) (well) | yes well and the car |
| (yes) (well) (work) (job) | yes well and hows it going |
| out-of-vocabulary | |||
| train/test split | oracle | ||
| realistic |

|
17% | |
| optimistic |

|
10% | |
Precision
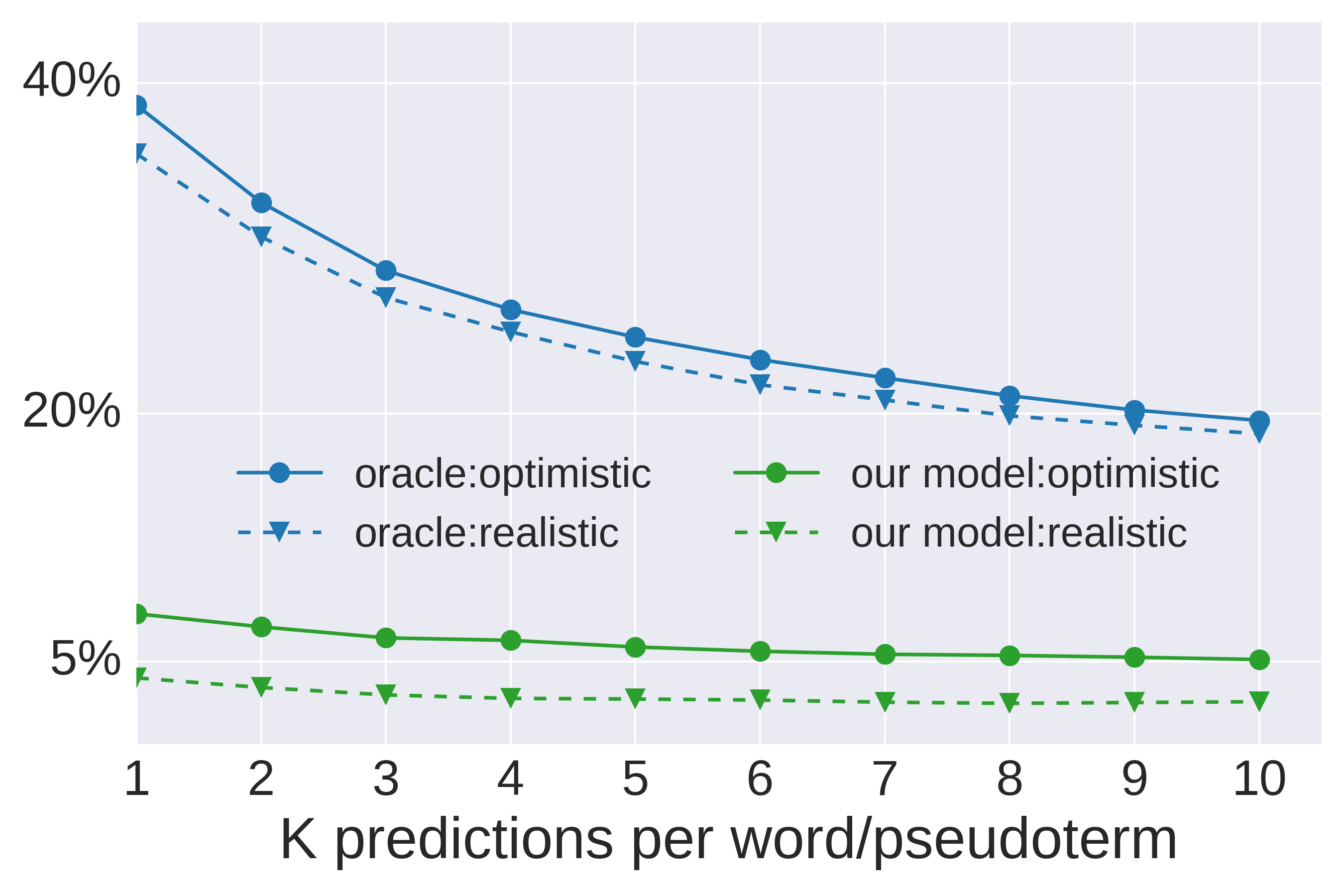
Recall
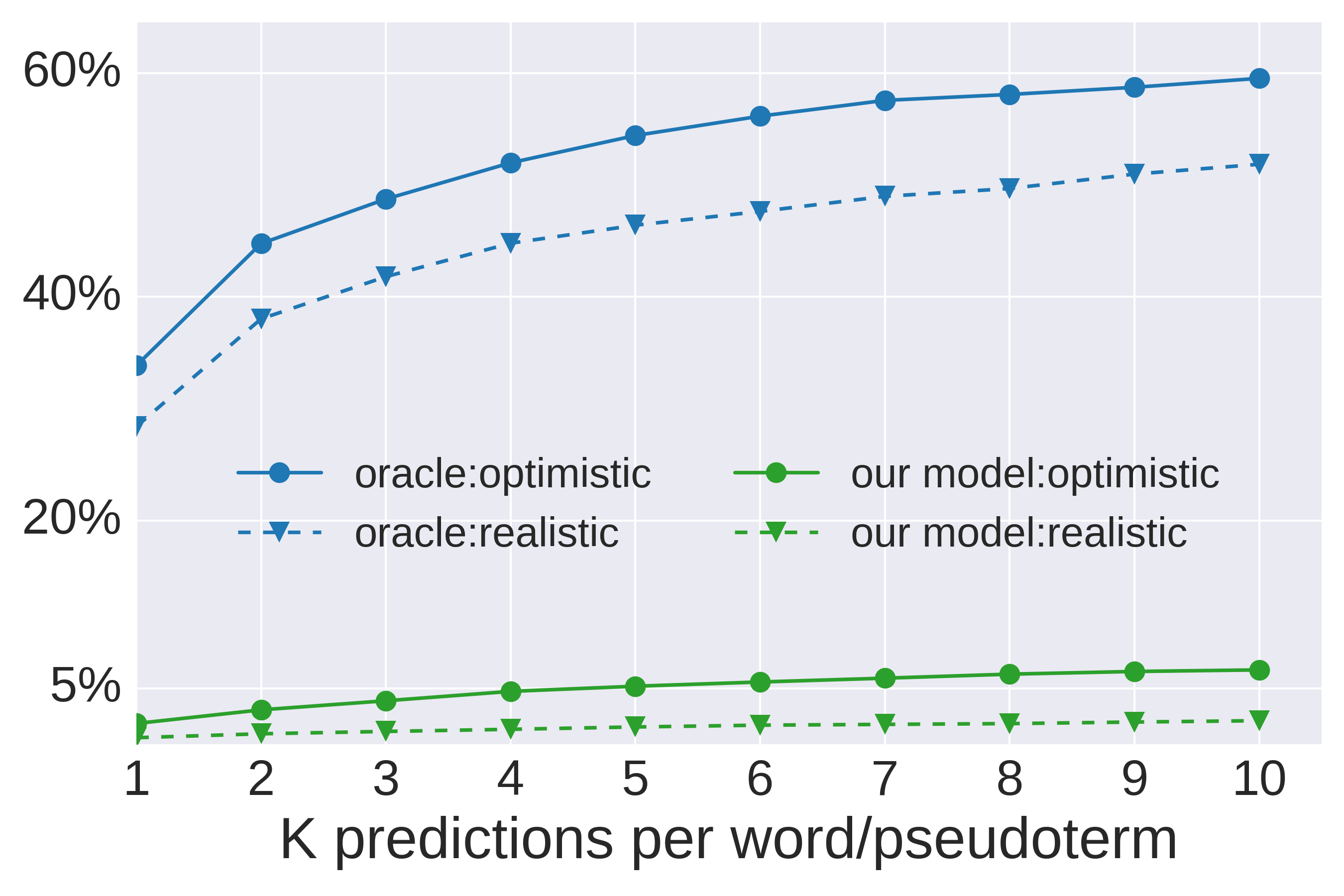
sample translations
| transcript | human translation | prediction | cómo anda el plan escolar | how is the school plan going | school, going |
| dile que le mando saludos | tell him that i say hi | say, hi | |
| sí con dos dientes menos | yeah with two teeth less | denture, yeah, teeth |
what next?
- simple method trained on ~10 hours audio + text can make some content word predictions
- previous work to improve accuracy of speech-to-pseudotext system
- recent work by Google shows promising results on ~100 hours of data using neural encoder-decoder
Thank you. Questions!
speech example
| our pred. | gold pred. | transcript | pseudotext |
|---|---|---|---|
| WELL COMPUTERS EVERYTHING | AHA EVERYTHING COMPUTERS | CO AJá COMPUTADORAS PUES | 1576 1737 11816 |
(☞゚∀゚)☞
speech example
| our pred. | gold pred. | transcript | pseudotext |
|---|---|---|---|
| TELL MAMY SAD FUN | SAD THINKING DAY BIRTHDAY | TRISTE PENSANDO DE QUE EL DíA DE TU CUMPLEAñOS | 293 348 379 2514 |
(ಥ﹏ಥ)
speech example
| our pred. | gold pred. | transcript | pseudotext |
|---|---|---|---|
| OH WELL 'S PROBLEM HEY WELL | AH BUENO ESA ES LA CUESTIóN OYE BUENO Y | 1354 |
(╯°□°)╯︵ ┻┻
Telephone call excerpt
spk 1: me mande mi acta de bautismo
spk 2: una nueva
spk 1: sí oye mamá
spk 3: sí mi hijo
spk 1: mi acta de bautismo
spk 3: sí
acoustic patterns
| cluster | source words | purity |
|---|---|---|
| (c2) cómo, trabajo, tal vas con | 0.18 | |
| claro, claro, claro, ... | 1 | |
| : ) | 0.95 | |
| mhmm | 1 |
acoustic clusters with errors = 66%
fragmentation
| audio | words |
|---|---|
| bien (female voice) | |
| bien (male voice) |
# acoustic clusters for bien = 271
accuracy of patterns across calls = ~10%